When the cloud stumbles, the world feels it. An Azure outage isn’t just a technical glitch—it’s a global disruption affecting businesses, governments, and millions of users. In this deep dive, we unpack everything you need to know about Azure outages: causes, impacts, responses, and how to prepare.




What Is an Azure Outage?

An Azure outage refers to any period when Microsoft Azure services become partially or fully unavailable to users. These disruptions can affect virtual machines, databases, storage, networking, or entire regions. While Azure boasts a 99.9% uptime SLA for most services, outages still occur due to infrastructure failures, software bugs, or human error.
Defining Service Disruption in the Cloud
Cloud service disruptions are not always total blackouts. They can manifest as degraded performance, intermittent connectivity, or specific service failures. Microsoft defines an outage as any incident where a service fails to meet its Service Level Agreement (SLA) commitments.
- Partial outage: Only certain services or regions are affected.
- Complete outage: All services in a region or globally are inaccessible.
- Latency issues: Services are up but respond slowly, impacting user experience.
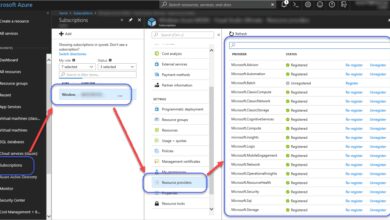
How Microsoft Classifies Azure Incidents
Microsoft uses a severity-based classification system for Azure incidents. According to the Microsoft Azure Availability documentation, incidents are ranked from Sev A (most critical) to Sev D (lowest impact).
- Sev A: Widespread service unavailability affecting critical workloads.
- Sev B: Significant degradation impacting multiple customers.
- Sev C: Isolated issues with moderate impact.
- Sev D: Minor issues with limited scope.
“An Azure outage is not just a technical event—it’s a business continuity challenge.” — Cloud Infrastructure Analyst, Gartner
Recent Major Azure Outage Events
Over the past few years, several high-profile Azure outages have made headlines, exposing vulnerabilities in even the most robust cloud platforms. These events provide valuable lessons for enterprises relying on cloud infrastructure.
February 2024 Global Azure Outage
One of the most significant Azure outages in recent memory occurred in February 2024. Users across Europe and North America reported widespread disruptions in Azure Virtual Machines, App Services, and Azure Active Directory.
- Duration: Over 8 hours of intermittent service.
- Root cause: A faulty firmware update in networking hardware triggered cascading failures.
- Impact: Major SaaS providers, healthcare systems, and financial institutions experienced downtime.
Microsoft’s post-incident report, published on the Azure Status History page, confirmed that the issue stemmed from a misconfigured router update that propagated across multiple data centers.
December 2022 Authentication Failure
In December 2022, a critical Azure Active Directory (Azure AD) outage prevented millions of users from logging into their accounts. This wasn’t just an inconvenience—it halted productivity for organizations using Microsoft 365, Teams, and third-party apps integrated with Azure AD.
- Symptoms: Users received “500 Internal Server Error” or “Authentication Failed” messages.
- Duration: Approximately 6 hours of global disruption.
- Resolution: Microsoft rolled back a recent identity platform update and restored services gradually.
The incident highlighted the risks of centralized identity management. As Microsoft Tech Community later explained, a logic error in token validation caused the authentication pipeline to fail.
Common Causes of Azure Outage
Understanding the root causes of Azure outages is essential for both cloud providers and consumers. While Microsoft invests heavily in redundancy and failover systems, no infrastructure is immune to failure.
Hardware and Network Failures
Despite automation and virtualization, physical infrastructure remains a point of vulnerability. Data center power outages, cooling system failures, or network hardware malfunctions can trigger an Azure outage.
- Power grid failures can knock out entire racks of servers.
- Fiber optic cable cuts disrupt inter-data center connectivity.
- Router or switch firmware bugs can propagate across regions.
In 2021, an Azure outage in the UK South region was traced back to a power distribution unit (PDU) failure, which took down multiple availability zones.
Software Bugs and Deployment Errors
One of the most common causes of Azure outage is flawed software updates. Automated deployment pipelines can push buggy code to production, especially in complex, distributed systems.
- A misconfigured API gateway can block traffic to critical services.
- Database schema changes can cause timeouts or crashes.
- Rolling updates without proper rollback mechanisms increase risk.
According to Microsoft’s engineering blog, over 40% of Sev A incidents between 2020 and 2023 were linked to deployment-related issues.
Human Error and Configuration Mistakes
Even with AI-driven operations, human intervention plays a role in managing Azure. Misconfigured firewalls, incorrect DNS settings, or accidental deletion of resources can lead to outages.
- An engineer might disable a critical load balancer during maintenance.
- Improper scaling policies can overload backend systems.
- Incorrect geo-replication settings can prevent failover.
“The most dangerous component in any cloud system is between the keyboard and the chair.” — Anonymous Azure Architect
Impact of Azure Outage on Businesses
The ripple effects of an Azure outage extend far beyond technical teams. Entire business operations can grind to a halt, leading to financial, reputational, and legal consequences.
Financial Losses and Downtime Costs
Downtime is expensive. For every minute an enterprise application is offline, thousands—or even millions—of dollars can be lost.
- E-commerce platforms lose sales during checkout failures.
- Financial institutions face transaction delays and compliance risks.
- SaaS companies may trigger SLA penalties for their own customers.
A 2023 study by Gartner estimated the average cost of cloud downtime at $5,600 per minute, with some enterprises losing over $1 million per hour during a major Azure outage.
Reputational Damage and Customer Trust
When a company’s services go down due to an Azure outage, customers often blame the brand—not Microsoft. This erosion of trust can have long-term consequences.
- Users may switch to competitors after repeated service interruptions.
- Brand perception suffers, especially in sectors like healthcare or finance.
- Social media amplifies negative sentiment during outages.
For example, during the 2024 Azure AD outage, several fintech startups faced public backlash despite the root cause being external. Their lack of contingency planning made them appear unreliable.
Compliance and Regulatory Risks
In regulated industries, uptime isn’t optional—it’s a legal requirement. Azure outages can lead to violations of GDPR, HIPAA, or PCI-DSS standards.
- Healthcare providers may fail to access patient records during emergencies.
- Financial audits may be delayed due to unavailable transaction logs.
- Data sovereignty laws may be breached if failover occurs in unauthorized regions.
Organizations must document their disaster recovery plans and prove due diligence in mitigating cloud risks.
How Microsoft Responds to Azure Outage
Microsoft has a well-established incident response framework to detect, mitigate, and communicate during an Azure outage. Transparency and speed are critical in restoring trust and service.
Incident Detection and Escalation
Azure’s monitoring systems use AI and machine learning to detect anomalies in real time. Metrics like latency, error rates, and resource utilization are continuously analyzed.
- Automated alerts trigger when thresholds are breached.
- On-call engineering teams are notified within minutes.
- Incident commanders are assigned to lead the response.
The Azure Monitor and Azure Sentinel platforms play a key role in early detection, helping to isolate issues before they escalate into full outages.
Communication and Status Updates
During an Azure outage, Microsoft provides real-time updates through the Azure Status Portal. This public dashboard shows the health of all services and regions.
- Incident timelines include start time, impact scope, and resolution status.
- Technical details are shared as they become available.
- Post-incident reports (PIRs) are published within 48 hours for major events.
However, some customers have criticized the lack of granular detail during active incidents. In response, Microsoft has improved its communication protocols, including direct email alerts for enterprise subscribers.
Post-Mortem Analysis and Prevention
After resolving an Azure outage, Microsoft conducts a thorough post-mortem analysis. These reports are publicly available and include root cause, timeline, and corrective actions.
- Engineering teams review logs, telemetry, and deployment records.
- Process improvements are implemented to prevent recurrence.
- Third-party auditors may be engaged for high-severity incidents.
For example, following the 2022 Azure AD outage, Microsoft introduced additional validation checks for identity platform updates and enhanced rollback capabilities.
How to Prepare for an Azure Outage
While you can’t prevent an Azure outage, you can significantly reduce its impact with proper planning and architecture. Resilience is not optional—it’s a design principle.
Design for High Availability and Redundancy
The foundation of outage preparedness is building resilient systems. Azure offers multiple tools to achieve high availability.
- Use Availability Zones to distribute workloads across physically separate data centers.
- Leverage Azure Traffic Manager or Front Door for global load balancing.
- Deploy applications in multiple regions for geo-redundancy.
For example, a banking application can run in both East US and West Europe, automatically failing over if one region goes down.
Implement Robust Monitoring and Alerting
You can’t fix what you can’t see. Proactive monitoring is essential for detecting early signs of an Azure outage.
- Set up Azure Monitor alerts for CPU, memory, and network usage spikes.
- Use Application Insights to track application health and user impact.
- Integrate with third-party tools like Datadog or Splunk for cross-platform visibility.
Custom dashboards can provide real-time visibility into service dependencies, helping teams respond faster during incidents.
Develop a Disaster Recovery Plan
Every organization using Azure should have a documented disaster recovery (DR) plan. This includes backup strategies, failover procedures, and recovery time objectives (RTO).
- Regularly back up databases using Azure Backup or SQL Database geo-backup.
- Test failover drills quarterly to ensure readiness.
- Define clear roles and communication protocols during outages.
Microsoft’s Azure Site Recovery service can automate replication and failover for virtual machines, minimizing downtime.
Alternatives and Multi-Cloud Strategies
Relying solely on Azure increases risk. A multi-cloud or hybrid strategy can provide redundancy and flexibility during an Azure outage.
Benefits of Multi-Cloud Architecture
Distributing workloads across multiple cloud providers reduces dependency on a single vendor.
- If Azure goes down, workloads can shift to AWS or Google Cloud.
- Competitive pricing and feature diversity improve cost efficiency.
- Geographic reach expands with access to more global data centers.
However, multi-cloud introduces complexity in management, security, and networking. Tools like Kubernetes, Terraform, and Istio help standardize operations across platforms.
Hybrid Cloud as a Safety Net
Hybrid cloud combines on-premises infrastructure with public cloud services. This model allows organizations to maintain critical systems locally during an Azure outage.
- Use Azure Stack to run Azure services on-premises.
- Keep backup domain controllers and authentication servers in-house.
- Leverage Azure Arc to manage resources across environments.
For regulated industries, hybrid setups offer better control over data sovereignty and compliance.
Failover and Load Balancing Across Clouds
Advanced architectures use global load balancers to route traffic based on health checks.
- DNS-based failover redirects users to AWS if Azure is down.
- Service meshes like Linkerd or Consul enable intelligent routing.
- Cloud-agnostic storage solutions (e.g., MinIO) ensure data portability.
While complex to implement, these strategies can reduce downtime from hours to seconds.
Future of Azure Reliability and AI-Driven Resilience
As cloud systems grow more complex, traditional monitoring and response methods are no longer sufficient. Microsoft is investing in AI and automation to predict and prevent Azure outages before they occur.
Predictive Maintenance Using AI
Azure is integrating machine learning models to predict hardware failures and performance bottlenecks.
- AI analyzes historical data to forecast disk failures or network congestion.
- Proactive replacements are scheduled before components fail.
- Anomaly detection identifies unusual patterns that may signal an impending outage.
For example, Azure’s Predictive Maintenance service for virtual machines can alert administrators to potential memory leaks or CPU saturation.
Self-Healing Systems and Automated Recovery
The future of cloud resilience lies in self-healing infrastructure. Azure is developing systems that automatically detect, isolate, and repair issues without human intervention.
- Autoscaling groups can replace unhealthy instances instantly.
- Database replicas can be promoted automatically during primary node failure.
- Network routing can be reconfigured in real time to bypass failed paths.
Microsoft’s Project Florian, an internal initiative, aims to reduce mean time to recovery (MTTR) to under 60 seconds for critical services.
Enhanced Transparency and Customer Empowerment
Microsoft is also focusing on giving customers more visibility and control during Azure outages.
- Real-time telemetry dashboards for enterprise customers.
- Customizable alerting and escalation workflows.
- API access to incident data for integration with internal systems.
These improvements aim to transform customers from passive observers into active participants in outage response.
What is an Azure outage?
An Azure outage is a period when one or more Microsoft Azure services are unavailable or performing below expected levels. This can range from regional disruptions to global service failures affecting millions of users.
How long do Azure outages typically last?
Most Azure outages are resolved within a few hours. However, major incidents—especially those involving core infrastructure—can last 6 to 12 hours or more, depending on the root cause and complexity of the fix.
Does Microsoft compensate for Azure outage downtime?
Yes. Microsoft offers service credits under its SLA if uptime falls below the guaranteed threshold (usually 99.9%). Customers can file claims through the Azure portal for eligible downtime.
How can I check if Azure is down right now?
You can visit the official Azure Status Portal to see real-time service health. Third-party sites like Downdetector also track user-reported issues.
Can I prevent my app from failing during an Azure outage?
While you can’t prevent the outage itself, you can design your application for resilience using redundancy, failover, and monitoring. A well-architected system can withstand partial outages with minimal user impact.
Understanding the nature, impact, and response to an Azure outage is crucial in today’s cloud-dependent world. From recent high-profile incidents to the technical causes and business consequences, this article has explored the full spectrum of what happens when the cloud falters. Microsoft continues to improve its systems with AI, automation, and transparency, but responsibility also lies with customers to design resilient architectures. By leveraging multi-cloud strategies, robust monitoring, and disaster recovery plans, organizations can minimize disruption and maintain trust—even when the cloud stumbles.
Recommended for you 👇
Further Reading: